Instance-based machine learning and model-based machine learning are two broad categories of machine learning algorithms that differ in their approach to learning and making predictions.
Instance-based learning algorithms, also known as lazy learning algorithms, do not build an explicit model from the training data. Instead, they store the entire training set and make predictions based on the similarity between new data points and the stored training data. Examples of instance-based learning algorithms include k-nearest neighbors, locally weighted learning, and instance-based learning algorithms.
Model-based learning algorithms, on the other hand, build an explicit model from the training data. This model can be used to make predictions on new data points. Examples of model-based learning algorithms include linear regression, logistic regression, and decision trees.
One of the key differences between instance-based and model-based learning algorithms is the way they handle unseen data. Instance-based learning algorithms make predictions based on the similarity between new data points and the stored training data. This means that they can make accurate predictions on unseen data, even if the data is not linearly separable. However, instance-based learning algorithms can be computationally expensive, especially when the training set is large.
Model-based learning algorithms, on the other hand, make predictions based on the model that has been built from the training data. This means that they can make accurate predictions on unseen data, even if the data is not linearly separable. However, model-based learning algorithms can be less accurate than instance-based learning algorithms on small training sets.
About Linearly Separable
Linearly separable refers to a scenario in data classification where two sets of points in a feature space can be completely separated by a straight line (in 2D), a plane (in 3D), or a hyperplane in higher dimensions. Essentially, if you can draw a line (or its higher-dimensional analog) such that all points of one class fall on one side of the line and all points of the other class fall on the other side, those points are considered linearly separable.
Another key difference between instance-based and model-based learning algorithms is the way they handle noise in the training data. Instance-based learning algorithms are more robust to noise in the training data than model-based learning algorithms. This is because instance-based learning algorithms do not build an explicit model from the training data. Instead, they store the entire training set and make predictions based on the similarity between new data points and the stored training data. This means that they are less likely to be affected by noise.
Model-based learning algorithms, on the other hand, are less robust to noise. This is because model-based learning algorithms build an explicit model from the training data. This model can be affected by noise, which can lead to inaccurate predictions on new data points.
An example instance approach predictor
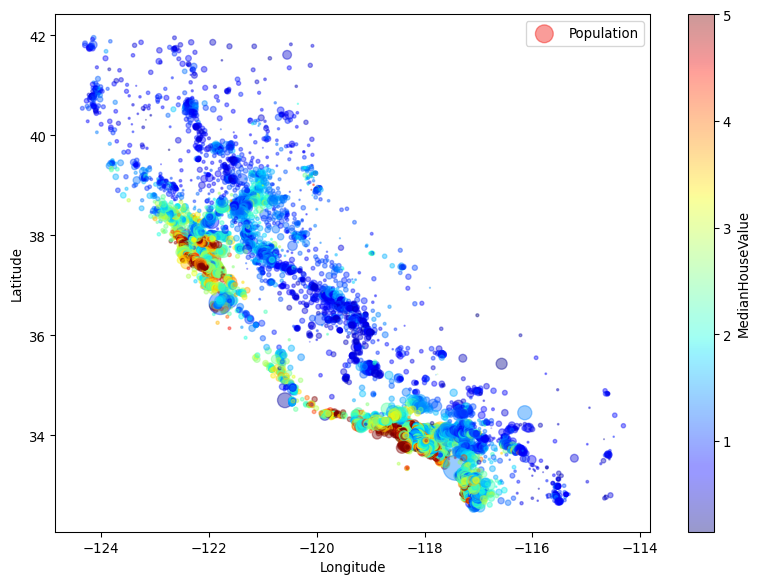
To illustrate the above, let us build a simple instance based predictor - in this case, based on the California Housing dataset which can be found both on Keras and SKLearn. This predictor will attempt to “guess” the median house price for a given California district census block group.
Let us start by getting a sense of what the dataset is about.
Show the code
import numpy as npfrom sklearn.datasets import fetch_california_housingimport matplotlib.pyplot as pltimport pandas as pd# Load the California housing datasethousing = fetch_california_housing()housing_df = pd.DataFrame(housing.data, columns=housing.feature_names)print(housing.DESCR)housing_df["MedianHouseValue"] = housing.targethousing_df.plot( kind="scatter", x="Longitude", y="Latitude", alpha=0.4, s=housing_df["Population"] /100, label="Population", figsize=(10, 7), c="MedianHouseValue", cmap=plt.get_cmap("jet"), colorbar=True,)plt.legend()
.. _california_housing_dataset:
California Housing dataset
--------------------------
**Data Set Characteristics:**
:Number of Instances: 20640
:Number of Attributes: 8 numeric, predictive attributes and the target
:Attribute Information:
- MedInc median income in block group
- HouseAge median house age in block group
- AveRooms average number of rooms per household
- AveBedrms average number of bedrooms per household
- Population block group population
- AveOccup average number of household members
- Latitude block group latitude
- Longitude block group longitude
:Missing Attribute Values: None
This dataset was obtained from the StatLib repository.
https://www.dcc.fc.up.pt/~ltorgo/Regression/cal_housing.html
The target variable is the median house value for California districts,
expressed in hundreds of thousands of dollars ($100,000).
This dataset was derived from the 1990 U.S. census, using one row per census
block group. A block group is the smallest geographical unit for which the U.S.
Census Bureau publishes sample data (a block group typically has a population
of 600 to 3,000 people).
A household is a group of people residing within a home. Since the average
number of rooms and bedrooms in this dataset are provided per household, these
columns may take surprisingly large values for block groups with few households
and many empty houses, such as vacation resorts.
It can be downloaded/loaded using the
:func:`sklearn.datasets.fetch_california_housing` function.
.. rubric:: References
- Pace, R. Kelley and Ronald Barry, Sparse Spatial Autoregressions,
Statistics and Probability Letters, 33 (1997) 291-297
And now that we have a reasonable idea of what data we are dealing with, let us define the predictor. In our case, we will be using a k-Nearest Neighbors regressor set for 10 neighbour groups.
About k-Nearest Neighbors
The k-nearest neighbors (k-NN) regressor is a straightforward method used in machine learning for predicting the value of an unknown point based on the values of its nearest neighbors. Imagine you’re at a park trying to guess the age of a tree you’re standing next to but have no idea how to do it. What you can do, however, is look at the nearby trees whose ages you do know. You decide to consider the ages of the 3 trees closest to the one you’re interested in. If those trees are 50, 55, and 60 years old, you might guess that the tree you’re looking at is around 55 years old—the average age of its “nearest neighbors.”
Show the code
from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import KNeighborsRegressorimport randomimport torchX, y = housing.data, housing.target# Initialize and seed random number generatorsseed =42np.random.seed(seed)random.seed(seed)torch.manual_seed(seed)if torch.cuda.is_available(): torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed)if torch.backends.mps.is_available(): torch.manual_seed(seed)# Load and split the California housing datasetX_train_full, X_test, y_train_full, y_test = train_test_split( X, y, test_size=0.2, random_state=seed)X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full)# Scale the featuresscaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_valid_scaled = scaler.transform(X_valid)X_test_scaled = scaler.transform(X_test)# Initialize the k-NN regressorknn_reg = KNeighborsRegressor(n_neighbors=10)# Train the k-NN modelknn_reg.fit(X_train_scaled, y_train)# Evaluate the modelscore = knn_reg.score( X_test_scaled, y_test) # This returns the R^2 score of the prediction# Making predictionspredictions = knn_reg.predict(X_test_scaled[:5])# Calculate relative differences as percentagesrelative_differences = ((predictions - y_test[:5]) / y_test[:5]) *100print(f"Model R^2 score: {score}")print(f"Predictions for first 5 instances: {predictions}")print(f"Actual values for first 5 instances: {y_test[:5]}")print(f"Relative differences (%): {relative_differences}")
Model R^2 score: 0.6863935783148378
Predictions for first 5 instances: [0.5714 0.6634 4.395005 2.6315 2.5254 ]
Actual values for first 5 instances: [0.477 0.458 5.00001 2.186 2.78 ]
Relative differences (%): [ 19.79035639 44.84716157 -12.1000758 20.37968893 -9.15827338]
We can see that based on the above regressor, our \(R^2\) is about 0.68. What this means is that 68% of the variance in the target variable can be explained by the features used in the model. In practical terms, this indicates a moderate to good fit, depending on the context and the complexity of the problem being modeled. However, it also means that 32% of the variance is not captured by the model, which could be due to various factors like missing important features, model underfitting, or the data inherently containing a significant amount of unexplainable variability.
Solving the same problem with a model approach
Let’s explore a model-based method for making predictions by utilizing a straightforward neural network structure. it is a simple feedforward model built for regression tasks. It starts with an input layer that directly connects to a hidden layer of 50 neurons. This hidden layer uses the ReLU activation function, which helps the model capture non-linear relationships in the data. After processing through this hidden layer, the data is passed to a single neuron in the output layer that produces the final prediction.
Additionally, the model is trained using the mean squared error (MSE) loss function, which is well-suited for regression because it penalizes larger errors more heavily. The use of stochastic gradient descent (SGD) helps in efficiently updating the model’s weights. We also add an early stopping mechanism to halt training when the validation loss stops improving, thereby preventing overfitting.
Show the code
import torch.nn as nnimport pytorch_lightning as plfrom torch.utils.data import DataLoader, TensorDatasetfrom pytorch_lightning.callbacks.early_stopping import EarlyStopping# Define the LightningModuleclass RegressionModel(pl.LightningModule):def__init__(self, input_dim):super().__init__()self.model = nn.Sequential( nn.Linear(input_dim, 50), nn.ReLU(), nn.Linear(50, 1) )self.loss_fn = nn.MSELoss()def forward(self, x):returnself.model(x)def training_step(self, batch, batch_idx): x, y = batch y = y.view(-1, 1) # Ensure proper shape y_hat =self(x) loss =self.loss_fn(y_hat, y)self.log("train_loss", loss)return lossdef validation_step(self, batch, batch_idx): x, y = batch y = y.view(-1, 1) y_hat =self(x) loss =self.loss_fn(y_hat, y)self.log("val_loss", loss, prog_bar=True)return lossdef test_step(self, batch, batch_idx): x, y = batch y = y.view(-1, 1) y_hat =self(x) loss =self.loss_fn(y_hat, y)self.log("test_loss", loss)return lossdef configure_optimizers(self): optimizer = torch.optim.SGD(self.parameters(), lr=0.01)return optimizer# Create TensorDatasets and DataLoaderstrain_dataset = TensorDataset( torch.tensor(X_train_scaled, dtype=torch.float32), torch.tensor(y_train, dtype=torch.float32),)valid_dataset = TensorDataset( torch.tensor(X_valid_scaled, dtype=torch.float32), torch.tensor(y_valid, dtype=torch.float32),)test_dataset = TensorDataset( torch.tensor(X_test_scaled, dtype=torch.float32), torch.tensor(y_test, dtype=torch.float32),)train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)valid_loader = DataLoader(valid_dataset, batch_size=32)test_loader = DataLoader(test_dataset, batch_size=32)# Initialize the model with the correct input dimensioninput_dim = X_train_scaled.shape[1]model = RegressionModel(input_dim=input_dim)# Set up EarlyStopping callbackearly_stop_callback = EarlyStopping( monitor="val_loss", patience=3, mode="min", verbose=False)# Train the model using PyTorch-Lightning's Trainertrainer = pl.Trainer( max_epochs=50, callbacks=[early_stop_callback], logger=False, enable_progress_bar=False, enable_checkpointing=False,)trainer.fit(model, train_loader, valid_loader)
With the model trained, let us evaluate performance and run a few predictions.
Show the code
# Evaluate the model on the test settest_results = trainer.test(model, test_loader)print(f"Test MSE: {test_results}")
# Make predictions for the first 5 test instancesmodel.eval()with torch.no_grad(): test_samples = torch.tensor(X_test_scaled[:5], dtype=torch.float32) predictions = model(test_samples).view(-1).numpy()# Calculate relative differences as percentagesrelative_differences = ((predictions - y_test[:5]) / y_test[:5]) *100print(f"Predictions for first 5 instances: {predictions}")print(f"Actual values for first 5 instances: {y_test[:5]}")print(f"Relative differences (%): {relative_differences}")
Predictions for first 5 instances: [0.5028435 1.6948755 3.745551 2.5731127 2.8087265]
Actual values for first 5 instances: [0.477 0.458 5.00001 2.186 2.78 ]
Relative differences (%): [ 5.41792436 270.0601482 -25.08912764 17.7087249 1.03332911]
Suggestions for improvement
While we’ve covered the basics, here are a few ideas to take this experiment further:
Dive deeper into the data: Understand which features most affect housing prices and why.
Tune the models: Experiment with different settings and configurations to improve accuracy.
Compare more metrics: Look beyond the \(R^2\) score to other metrics like MAE or MSE for a fuller picture of model performance.
Explore model limitations: Identify and address any shortcomings in the models used.
Final remarks
In this experiment, we’ve explored two different ways to predict housing prices in California: using instance-based learning with a k-Nearest Neighbors (k-NN) regressor and model-based learning with a neural network. Here’s a straightforward recap of what we learned:
Instance-Based Learning with k-NN: This method relies on comparing new data points to existing ones to make predictions. It’s pretty straightforward and works well for datasets where the relationship between data points is clear. Our k-NN model did a decent job, explaining about 68% of the variance in housing prices, showing it’s a viable option but also highlighting some limits, especially when dealing with very large datasets.
Model-Based Learning with Neural Networks: This approach creates a generalized model from the data it’s trained on. Our simple neural network, equipped with early stopping to prevent overfitting, showcased the ability to capture complex patterns in the data. It requires a bit more setup and tuning but has the potential to tackle more complicated relationships in data.
Each method has its place, depending on the specific needs of your project and the characteristics of your dataset. Instance-based learning is great for simplicity and direct interpretations of data, while model-based learning can handle more complex patterns at the expense of needing more computational resources and tuning.