How GPU’s work, an explainer using the Mandelbrot set
mandelbrot sets and parallelism
Experiments
GPU
Published
February 9, 2025
Every day pretty much all of us either uses or hears about the mythical GPU, the Graphics Processing Unit. It’s the thing that makes your games, video renders, and your machine learning models train faster. But how does it achieve that? What makes it different from a CPU?
We will do a quick explainer which should give you a good intuition using the Mandelbrot set. The Mandelbrot set is a fractal, a set of complex numbers that when iterated through a function, either diverges to infinity or stays bounded, it is the boundary between these two regions. The Mandelbrot set is a great example to use because it’s a simple function that can be parallelized easily.
A quick diversion into parallelism
During my university days I had a quick course on parallelism, where we were asked how we could parallelize the computation of the Mandelbrot set. The answer is simple, we can calculate each pixel independently, since at its core, calculating the set involves applying a function to each complex number to determine if it belongs to the set or not.
Back then the approach I followed was to divide the image into an \(n x n\) grid and assign each grid to a separate networked computer, which would then calculate the pixels in that grid, and write results to a network shared file (this was back in the day where RPC was barely a thing). This is a simple form of parallelism, and it’s called embarrassingly parallel.
Most GPU computations are embarrassingly parallel, and this is why they are so good at simple parallelism workloads. They have thousands of cores, and each core can act independently to compute a fragment of the workload.
They are adept at machine learning and AI workloads equally because most of the computations in these fields are matrix multiplications, which can be parallelized easily.
The Mandelbrot set
The Mandelbrot set is defined by the following function:
\[
f(z) = z^2 + c
\]
where \(z\) is a complex number, and \(c\) is a constant complex number. We can iterate this function, and if the magnitude of \(z\) is greater than 2, then we can say that the function diverges to infinity. If it doesn’t, then it stays bounded. The Mandelbrot set is the boundary between these two regions.
Further below we will show a rendered image of the Mandelbrot set, but first, let’s write a simple Python function to calculate it.
Calculating the Mandelbrot set with no parallelism
Let’s start by writing a simple, naive function to calculate the Mandelbrot set. This function uses no parallelism, and it’s a simple for loop that iterates over each pixel in the image and calculates each using the CPU only. It basically iterates over columns and rows and computes whether that particular point diverges or not as nested loops.
For a width of 500 and height of 500, this function will compute \(250000\) pixels, for a width of 1000 and height of 1000, it will compute \(1000000\) pixels, and so on. The time taken for this function to run increase as \(O(n^2)\) where \(n\) is the width or height of the image.
Show the code
def compute_mandelbrot_iterations(width, height, max_iter): real_min, real_max =-2, 1 imag_min, imag_max =-1.5, 1.5 real_step = (real_max - real_min) / (width -1) imag_step = (imag_max - imag_min) / (height -1)# Initialize a 2D list to hold iteration counts. iter_counts = [[0for _ inrange(width)] for _ inrange(height)]for j inrange(height): imag = imag_min + j * imag_stepfor i inrange(width): real = real_min + i * real_step c =complex(real, imag) z =0j count =0while count < max_iter: z = z * z + c# Check divergence: if |z|^2 > 4 then break.if (z.real * z.real + z.imag * z.imag) >4:break count +=1 iter_counts[j][i] = countreturn iter_counts
Calculating the Mandelbrot set with parallelism
While the above function is simple, it is not the most efficient. Because it is basically a big matrix operation (an image is a matrix), we can parallelize it easily using a number of frameworks which offer matrix operations. Let’s investigate how we would do this using a number of libraries.
For this example, we will show how to achieve it using numpy, pytorch and Apple’s mlx. They all offer a similar API, and can be used virtually interchangeably. They offer a set of functionality which allows you to perform matrix operations on either the CPU and GPU:
Vectorized Operations: They all let you perform elementwise operations on entire arrays/tensors without explicit loops, which boosts performance.
Broadcasting: NumPy, PyTorch, and MLX support broadcasting, allowing operations on arrays of different shapes — great for aligning matrices without manual reshaping.
Optimized Backends: Under the hood, they rely on highly optimized C/C++ libraries (like BLAS/LAPACK or Apple’s Accelerate framework for MLX) to perform computations quickly.
Multi-dimensional Data Handling: They all offer robust support for multi-dimensional arrays (or tensors), making them well-suited for tasks ranging from basic linear algebra to complex machine learning computations.
Numpy
Let’s start with an implementation of the compute_mandelbrot_iterations function using numpy, entirely with array (or matrix) operations.
Show the code
import numpy as npdef compute_mandelbrot_numpy( width: int=500, height: int=500, max_iter: int=30) -> np.ndarray:# Create linearly spaced real and imaginary parts and generate a complex grid. real = np.linspace(-2, 1, width) imag = np.linspace(-1.5, 1.5, height) X, Y = np.meshgrid(real, imag, indexing="xy") c = X +1j* Y# Initialize z and an array to hold the iteration counts z = np.zeros_like(c) iter_counts = np.zeros(c.shape, dtype=np.int32)for _ inrange(max_iter):# Create a mask for points that have not yet diverged mask = np.abs(z) <4ifnot mask.any():break# Update z and iteration counts only where |z| < 4 z = np.where(mask, z * z + c, z) iter_counts = np.where(mask, iter_counts +1, iter_counts)return iter_counts
This function starts by generating a grid of complex numbers using matrix operations, which is key for parallel computation. It first creates two linearly spaced arrays for the real and imaginary parts using np.linspace, and then builds two 2D grids with np.meshgrid — one for the real values and one for the imaginary values. These grids are combined into a single complex grid c (where each element is of the form x + 1j * y), and this process happens all at once without the need for explicit loops, leveraging NumPy’s vectorized operations.
Next, the code initializes two arrays of the same shape as c: one for the iterative values z (starting at zero) and one to keep track of the iteration counts. The main computation occurs in a loop where, in each iteration, the code computes the absolute value of every element in z simultaneously using np.abs(z) and creates a boolean mask that identifies the elements where |z| < 4. This mask is then used to update z and iter_countsin one go vianp.where`, ensuring that only the elements that haven’t diverged (i.e., where the condition holds) are updated.
Because these operations — creating the grid, computing absolute values, applying the mask, and updating arrays — are all performed on entire arrays at once, they are handled in parallel by optimized C code under the hood. This eliminates the need for slow, explicit Python loops, which is why such an approach is highly efficient for intensive computations like generating the Mandelbrot set. The combination of vectorized operations and conditional updates not only makes the code concise but also allows the underlying hardware to execute many operations concurrently, resulting in much faster computation.
PyTorch
Now let us do the same but with the pytorch library, except for the line c = X.t() + 1j * Y.t(), the code is identical to the numpy implementation. The t() function is used to transpose the matrix, and the + and * operators are overloaded to perform elementwise addition and multiplication, respectively. This allows us to create the complex grid c in a single line, just like in the numpy version.
Tip
The reason you see a transpose in PyTorch is because its grid creation defaults to a different dimension ordering than numpy’s. In numpy, when you use np.meshgrid with indexing='xy', the resulting arrays have the first dimension corresponding to the y-axis and the second to the x-axis, matching common image coordinate conventions. pytorch’s torch.meshgrid, on the other hand, typically returns tensors where the dimensions are swapped relative to that layout. By transposing (.t()) the pytorch tensors, you align the dimensions so that the complex grid c ends up with the same arrangement as in numpy. This ensures that each element in c correctly corresponds to the intended coordinate in the complex plane.
Show the code
import torchdef compute_mandelbrot_torch( width: int=500, height: int=500, max_iter: int=30, device: str="cpu") -> torch.Tensor: real = torch.linspace(-2, 1, steps=width, device=device) imag = torch.linspace(-1.5, 1.5, steps=height, device=device) X, Y = torch.meshgrid(real, imag, indexing="xy") c = X.t() +1j* Y.t() z = torch.zeros_like(c) iter_counts = torch.zeros(c.shape, device=device, dtype=torch.int32)for _ inrange(max_iter): mask = torch.abs(z) <4ifnot mask.any():break z = torch.where(mask, z * z + c, z) iter_counts = torch.where(mask, iter_counts +1, iter_counts)return iter_counts
Because we are using pytorch tensors, we can offload the workload onto a GPU by setting the device parameter to 'cuda' or 'mps'. This tells pytorch to use the GPU for all subsequent operations, which will significantly speed up the computation. The rest of the code remains the same, with the same vectorized operations and conditional updates as in the NumPy version.
The difference being that when using the GPU, the operations will run concurrently on the GPU cores, which are optimized for parallel computation. For example, when running z = torch.where(mask, z * z + c, z) on a GPU, each element in z, mask, and c can be processed simultaneously by different cores, allowing for massive speedups compared to sequential execution on a CPU. Effectivelly we will be “painting” the Mandelbrot set in one single operation rather than pixel by pixel.
Apple’s MLX
Apple’s MLX offers an API which is virtually the same as PyTorch and NumPy, and it can be used interchangeably with them. The only difference is that it is optimized for Apple hardware, and it can be used on Apple Silicon.
Let’s put all the above together and render the Mandelbrot set with each different method. Each of compute_mandelbrot_* returns a 2D array of integers, where each integer represents the number of iterations it took for that pixel to diverge. We will then use matplotlib to render the image.
That confirms that each of the methods above is correct, and that they all yield the same result. The only difference is the speed at which they compute the Mandelbrot set!
Timing the functions
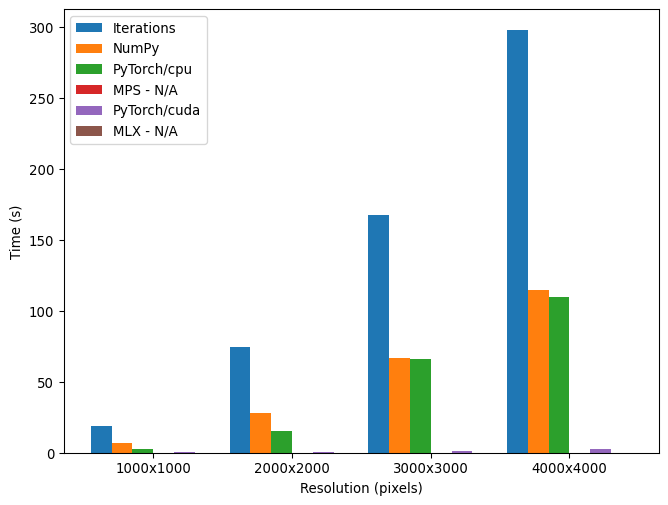
So we can easily contrast and compare the speed of each of the above functions, let’s time them using the time module in Python at different resolutions (width and height). We will see the difference in parallelism between methods which rely entirely on the CPU and those which offload the computation to the GPU. All timings are in seconds.
And finally let us put the above results in an intuitive visual representation, so we can see the difference in speed between the different methods.
Show the code
import matplotlib.ticker as tickerimport numpy as np # Make sure NumPy is importedresolutions_numeric = [int(row[0].split("x")[0]) for row in table_data]methods = header[1:]num_res =len(resolutions_numeric)num_methods =len(methods)x = np.arange(num_res)bar_width =0.15fig, ax = plt.subplots(figsize=(8, 6))for i, method inenumerate(methods): times = []for row in table_data: value = row[i +1] # skip resolution column times.append(float(value) if value !="N/A"else0) offset = (i - num_methods /2) * bar_width + bar_width /2 ax.bar(x + offset, times, bar_width, label=method)ax.set_xlabel("Resolution (pixels)")ax.set_ylabel("Time (s)")ax.set_xticks(x)ax.set_xticklabels([f"{res}x{res}"for res in resolutions_numeric])formatter = ticker.ScalarFormatter()formatter.set_scientific(False)ax.yaxis.set_major_formatter(formatter)ax.legend()plt.show()
You can see that GPU methods are significantly faster than the CPU because of its inherent parallelism. The more cores you have, the faster the computation will be. This is why GPUs are so good at parallel workloads, and why they are so adept to machine learning and AI workloads - deep down, they are just matrix operations using embarrasingly parallel workloads.