Show the code
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")Using device: cudaMachine learning never sleeps, and its latest wake-up call is the cutting-edge Kolmogorov-Arnold Networks (KANs), as detailed in this NSF paper. Stepping up from the tried-and-true Multi-Layer Perceptrons (MLPs), KANs are not just another update — they’re very much a whole new different approach. They’re designed to outpace their predecessors in accuracy and efficiency, and offer a clearer window into how they make decisions.
Let’s briefly explore the theoretical underpinnings of KANs, their practical applications, and the implications they hold for the future of AI, mostly without the use of any formulas.
Inspired by the Kolmogorov-Arnold representation theorem, KANs reconfigure the typical neural network architecture by replacing fixed activation functions on nodes with learnable activation functions on edges, eliminating linear weights entirely. This change, though seemingly simple, enables KANs to outperform MLPs substantially in various tasks, including data fitting, classification and partial differential equation (PDE) solving.
The theoretical implications of this are profound. Traditionally, MLPs have been constrained by their reliance on a large number of parameters and their opaque, black-box nature. KANs, by contrast, introduce a model where each “weight” is a univariate function parameterized as a spline, allowing for a more nuanced interaction with data. This structure not only reduces the number of necessary parameters but also enhances the interpretability of the model by making its operations more transparent and understandable to practitioners.
Empirically, KANs have demonstrated superior performance over MLPs in several benchmarks. The original paper highlights their ability to achieve comparable or superior accuracy with significantly smaller models. For example, in tasks involving the solving of partial differencial equations, a smaller-sized KAN outperformed a larger MLP both in terms of accuracy and parameter efficiency—achieving a hundredfold increase in accuracy with a thousandfold reduction in parameters.
Moreover, the adaptability of KANs to various data scales and their ability to learn and optimize univariate functions internally provide them with a distinct advantage, particularly in handling high-dimensional data spaces. This ability directly addresses and mitigates the curse of dimensionality, a longstanding challenge in machine learning.
The “curse of dimensionality” describes several challenges that occur when handling high-dimensional spaces — spaces with a large number of variables — that do not arise in lower-dimensional environments. As dimensions increase, the volume of the space expands exponentially, leading to data becoming sparse. This sparsity complicates gathering sufficient data to ensure statistical methods are reliable and representative of the entire space.
For example, consider trying to uniformly fill a cube with data points. In a three-dimensional space, you might need 1000 samples for decent coverage (10 samples along each dimension). However, in ten dimensions, you’d need \(10^{10}\) samples, which quickly becomes impractical.
\[ N(d) = 10^d \]
Where \(\mathbf{N(d)}\) represents the number of samples needed, and \(\mathbf{d}\) is the number of dimensions.
Additionally, in high-dimensional spaces, the concept of distance between data points becomes less meaningful as points tend to appear equidistant from one another. This undermines the effectiveness of distance-based methods such as clustering and nearest neighbors.
With more dimensions, the complexity of managing and analyzing data also increases, often requiring more computational power and sophisticated algorithms. Furthermore, there’s a heightened risk of overfitting models in high dimensions. Overfitting occurs when a model is excessively complex, capturing random noise instead of the underlying data patterns, making it poor at predicting new or unseen data. These factors collectively underscore the challenges posed by the curse of dimensionality in data analysis and machine learning.
The implications of KANs extend beyond just enhanced performance metrics. By facilitating a more intuitive understanding of the underlying mathematical and physical principles, KANs can act as catalysts for scientific discovery. The whitepaper describes instances where KANs have helped rediscover mathematical and physical laws, underscoring their potential as tools for scientific inquiry and exploration.
Moreover, the inherent interpretability of KANs makes them valuable for applications requiring transparency and explainability, such as in regulated industries like finance and healthcare. This characteristic could lead to broader acceptance and trust in AI solutions, paving the way for more widespread implementation of machine learning technologies in sensitive fields.
While KANs represent a significant leap forward, they are not without challenges. There are potential issues with the scalability of the spline-based approach, especially as the complexity of tasks increases. Future research will need to focus on optimizing these models for larger scale applications and exploring the integration of KANs with other types of neural networks to enhance their versatility.
Additionally, the full potential of KANs in terms of training dynamics, computational efficiency, and compatibility with existing machine learning frameworks remains to be fully explored. These areas offer rich avenues for further research and development.
To illustrate the fundamental difference between KANs and MLPs, let’s consider a simple example. Suppose we have a dataset with two features, \(\mathbf{x_1}\) and \(\mathbf{x_2}\), and a binary target variable \(\mathbf{y}\). We want to build a simple classification model to predict \(\mathbf{y}\) based on the input features. Furthermore, let us pick a dataset that is not linearly separable and which would present a challenge for any ML model.
Let’s create a simple, synthetic dataset with SKLearn to demonstrate a KAN in action. In this case we will use the make_circles function to generate a toy dataset that is not linearly separable.
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")Using device: cudaimport sklearn.datasets as datasets
Circles_points_train, Circles_label_train = datasets.make_circles(
n_samples=1000, shuffle=True, factor=0.5, noise=0.10, random_state=42
)
Circles_points_test, Circles_label_test = datasets.make_circles(
n_samples=1000, shuffle=True, factor=0.5, noise=0.10, random_state=43
)
dataset = {}
dataset["train_input"] = (
torch.from_numpy(Circles_points_train).float().to(device)
) # Ensure that the data is float and on the correct device
dataset["train_label"] = torch.from_numpy(Circles_label_train).to(device)
dataset["test_input"] = torch.from_numpy(Circles_points_test).float().to(device)
dataset["test_label"] = torch.from_numpy(Circles_label_test).to(device)
X = dataset["train_input"]
y = dataset["train_label"]
print(X.shape, y.shape)torch.Size([1000, 2]) torch.Size([1000])The dataset has 1000 samples, 2 features, and 2 classes. We will split the dataset into training and testing sets, and then train a KAN model on the training data and evaluate its performance on the test data. Let’s have a look at what it looks like.
# Plot X and y as 2D scatter plot
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.scatter(X[y == 0, 0].cpu(), X[y == 0, 1].cpu(), color="blue")
plt.scatter(X[y == 1, 0].cpu(), X[y == 1, 1].cpu(), color="red")
plt.show()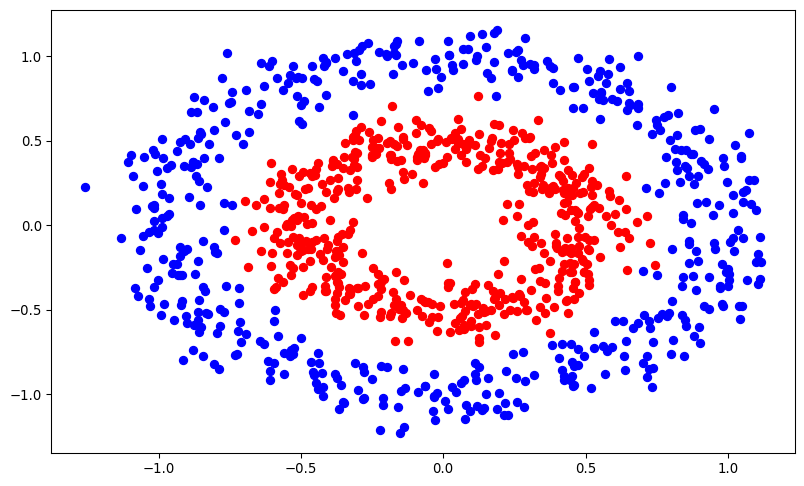
We can clearly see this is not a linearly separable dataset, as the two classes are intertwined in a circular pattern. This should be a good test for the KAN approach.
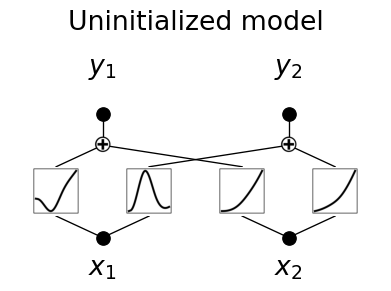
Let’s now create the model. It will have two input nodes, and two output nodes, one for each class. The key difference from an MLP is that the weights are replaced by learnable activation functions on the edges connecting the nodes.
import kan as kan
model = kan.KAN(width=[2, 2], grid=3, k=3, device=device)checkpoint directory created: ./model
saving model version 0.0One great thing about the KAN pytorch implementation is that it alows us to easily visualize the model structure. Let’s have a look at it.
# Plot the uninitialized model
model(X)
model.plot(
beta=100,
in_vars=[r"$x_1$", r"$x_2$"],
out_vars=[r"$y_1$", r"$y_2$"],
title="Uninitialized model",
)
Now let us define two metric functions to evaluate the model performance - one for training accuracy, and one for test accuracy. We will then train it on the data and evaluate its performance.
def train_acc():
return torch.mean(
(
torch.argmax(model(dataset["train_input"]), dim=1) == dataset["train_label"]
).float()
)
def test_acc():
return torch.mean(
(
torch.argmax(model(dataset["test_input"]), dim=1) == dataset["test_label"]
).float()
)
device = torch.device("mps" if torch.mps.is_available() else "cpu")
device = torch.device("cuda" if torch.cuda.is_available() else device)
print(f"Using device: {device}")
x = torch.ones(1, device=device)
print(x)
results = model.fit(
dataset,
opt="LBFGS",
steps=50,
metrics=(train_acc, test_acc),
loss_fn=torch.nn.CrossEntropyLoss(),
)
results["train_acc"][-1], results["test_acc"][-1]Using device: cuda
tensor([1.], device='cuda:0')saving model version 0.1(0.9980000257492065, 0.9890000224113464)That training run took just a few seconds to complete, and the model achieved a test accuracy of 0.98, which is quite impressive given the complexity of the dataset! This demonstrates the power of KANs in handling non-linearly separable data and achieving high accuracy with a simple model.
Let’s look at the training performance.
# Plot the training and test accuracy
import matplotlib.pyplot as plt
plt.plot(results["train_acc"], label="train")
plt.plot(results["test_acc"], label="test")
plt.legend()
plt.show()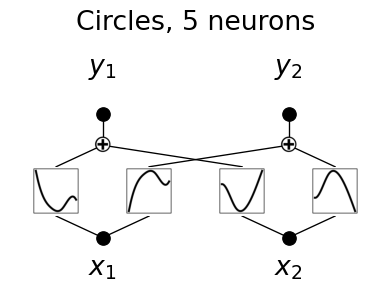
We can see that the training accuracy increases rapidly and converges to a high value, indicating that the model is learning effectively from the data just after a few training steps.
Let’s look at it after training.
model.plot(
title="Circles, 5 neurons",
in_vars=[r"$x_1$", r"$x_2$"],
out_vars=[r"$y_1$", r"$y_2$"],
beta=20,
)
You will have noticed that the shape of the activation functions has changed after training. This is because the model has learned the optimal activation functions to map the input data to the output classes effectively.
Remember that we mentioned that KANs are more interpretable than MLPs? Let’s look at the symbolic representation of the activation functions learned by the model. This is a unique feature of KANs that allows us to understand how the model is making decisions, and which you can’t get from a traditional MLP network.
function_library = [
"x",
"x^2",
"x^3",
"x^4",
"exp",
"log",
"sqrt",
"tanh",
"sin",
"tan",
"abs",
]
model.auto_symbolic(lib=function_library)
formula1, formula2 = model.symbolic_formula()[0]fixing (0,0,0) with x^2, r2=0.944023072719574, c=2
fixing (0,0,1) with x^2, r2=0.9523342251777649, c=2
fixing (0,1,0) with sin, r2=0.9956939220428467, c=2
fixing (0,1,1) with sin, r2=0.9956303238868713, c=2
saving model version 0.2formula1\(\displaystyle 65.6034606510272 \left(0.0600098280338495 - x_{1}\right)^{2} - 41.0008277893066 \sin{\left(2.02343988418579 x_{2} + 1.59663987159729 \right)} + 0.722492218017578\)
formula2\(\displaystyle - 62.1148479768263 \left(0.0699051752569734 - x_{1}\right)^{2} - 42.7506561279297 \sin{\left(2.01999974250793 x_{2} - 7.80703973770142 \right)} - 3.6636848449707\)
We get two formulas, one for each class, that represent the activation functions learned by the model. With this, we can now calculate the accuracy of the determined symbolic functions on the test data.
# Calculate the accuracy of the formula
import numpy as np
def symbolic_acc(formula1, formula2, X, y):
batch = X.shape[0]
correct = 0
for i in range(batch):
logit1 = np.array(formula1.subs("x_1", X[i, 0]).subs("x_2", X[i, 1])).astype(
np.float64
)
logit2 = np.array(formula2.subs("x_1", X[i, 0]).subs("x_2", X[i, 1])).astype(
np.float64
)
correct += (logit2 > logit1) == y[i]
return correct / batch
print(
"formula train accuracy:",
symbolic_acc(formula1, formula2, dataset["train_input"], dataset["train_label"]),
)
print(
"formula test accuracy:",
symbolic_acc(formula1, formula2, dataset["test_input"], dataset["test_label"]),
)formula train accuracy: tensor(0.9870, device='cuda:0')
formula test accuracy: tensor(0.9870, device='cuda:0')The symbolic functions learned by the model achieve a test accuracy of 0.98, which is very close to the model itself. This demonstrates the power of KANs in learning interpretable activation functions that can effectively map input data to output classes.
As a last step, let’s visualize the decision boundary learned by the model. This will help us understand how the model is separating the two classes in the input space.
# Plot the symbolic formula as a Plotly contour plot
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-1.5, 1.5, 100)
y = np.linspace(-1.5, 1.5, 100)
X, Y = np.meshgrid(x, y)
Z = np.zeros_like(X)
for i in range(100):
for j in range(100):
logit1 = np.array(formula1.subs("x_1", X[i, j]).subs("x_2", Y[i, j])).astype(
np.float64
)
logit2 = np.array(formula2.subs("x_1", X[i, j]).subs("x_2", Y[i, j])).astype(
np.float64
)
# Determine the class by comparing the logits
Z[i, j] = logit2 > logit1
plt.figure(figsize=(10, 6))
plt.contourf(X, Y, Z)
plt.colorbar()
plt.scatter(
Circles_points_train[:, 0],
Circles_points_train[:, 1],
c=Circles_label_train,
cmap="coolwarm",
)
plt.show()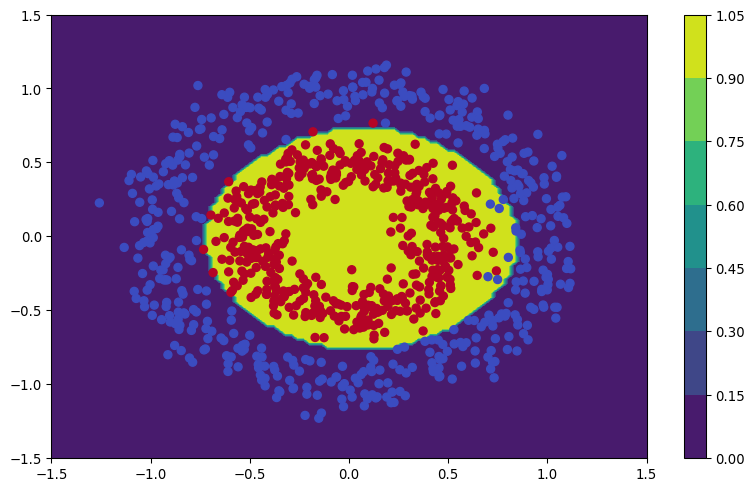
The model has learned a complex decision boundary that effectively separates the two classes in the input space. It’s clear that it has captured the underlying patterns in the data and can make accurate predictions based on them.

KANs represent a significant advancement in the field of machine learning, offering a more efficient, interpretable, and powerful alternative to traditional MLPs. Their ability to learn activation functions on edges, rather than fixed weights on nodes, enables them to handle complex, high-dimensional data and achieve high accuracy with fewer parameters.
The theoretical foundation of KANs, inspired by the Kolmogorov-Arnold representation theorem, provides a solid basis for their design and performance. Their practical applications span a wide range of tasks, from data fitting to PDE solving, and their interpretability makes them valuable in scientific and regulated industries.
While challenges remain in scaling KANs and integrating them with existing frameworks, their potential for future research and development is vast.